Why DeepSeek shocked AI experts and gained global fame
Off the chart technical chops.

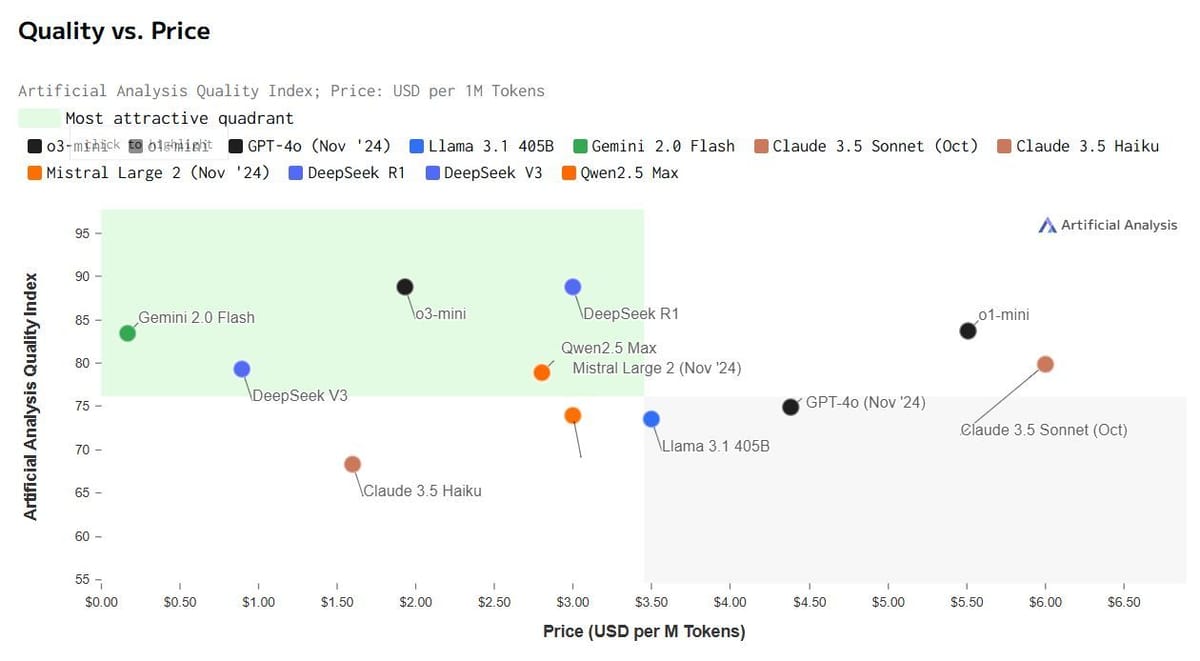
You've read a lot about DeepSeek since last week. Hyperbole aside, here's why it is so good.
There's a lot going around right now about DeepSeek, much of it described using lofty language. What exactly does it do differently?
I explain in 4 points:
Incredible optimisations, skill
Limited to crippled China-only H800 GPUs, the DeepSeek team worked hard to optimise the limited resources they had.
- They used 8-bit floating point numbers (FP8) instead of traditional 32-bit (FP32) numbers. To make this work, they created a new system to break numbers into small tiles and blocks to switch between FP8 and FP32. Result: 75% reduction in memory usage.
- To get more from their GPUs, the team implemented assembly-like programming (Nvidia PTX) instead of CUDA. Using PTX, they made optimisations to GPUs for efficiency and even reassigned some cores for server communication - likely for data compression to overcome limited bandwidth.
Reinforcement learning
DeepSeek was trained mainly using reinforcement learning with minimum reliance on supervised fine-tuning commonly used to train AI models.
- By relying mainly on automated feedback instead of human feedback, the cost and training time are significantly reduced.
- Or as described by Conor Grennan, "Most AI models need to see 1000's of solved examples first - DeepSeek let their model learn math through pure trial and error... like watching a kid figure out algebra by experimenting."
They did it better
The Mixture-of-Experts (MoE) architecture used by DeepSeek isn't new. MoE divides an AI model into sub-networks or experts for specific data or tasks.
OpenAI uses it. But where GPT-4 is believed to use just 16 expert models, DeepSeek did it at a far more granular level, thanks to various architectural innovations.
As a result, the DeepSeek model activates only 37 billion parameters out of its total 671 billion parameters for any given task. The result is similar performance at a fraction of the compute.
The proof is in the price
The biggest jaw-dropper is the cost of accessing it via API. For every million output tokens:
DeepSeek R1: $2.19
OpenAI o1: $60.00
I'm not sure if the price is a result of DeepSeek's efficiency or improvements at the inference level, with some literature suggesting it uses Huawei's Ascend GPUs.
Looking ahead
DeepSeek released everything under the generous MIT license, including training secrets - far more than Meta's (not really open) open-source Llama.
And if DeepSeek shared so much voluntarily, what other tricks does the team have up its sleeve?



