Tech giants are using your data to train their AI
When does it stop? YouTube videos, copyrighted books, online content - all stolen to train AI.

When does it stop? YouTube videos, copyrighted books, online content stolen to train AI.
There's an answer. And it's 2026. I'll explain in a moment.
According to the New York Times, tech giants such as OpenAI, Meta, and Google have cut corners in their quest to harvest enough data for AI.
On the prowl for data
They have turned to various sources to feed the ravenous appetites of training ever-larger large-language models, or LLMs.
- YouTube videos, podcasts.
- Images on social media.
- Wikipedia articles.
- Code on GitHub.
... were all used as training data.
OpenAI's Whisper, an automatic speech recognition service, was in fact created to pilfer YouTube videos.
Why didn't Google stop them? Turns out it was doing the same and a complaint might hence backfire.
Other content being fed into the maws of LLMs:
- Published books.
- Online articles.
- Facebook posts.
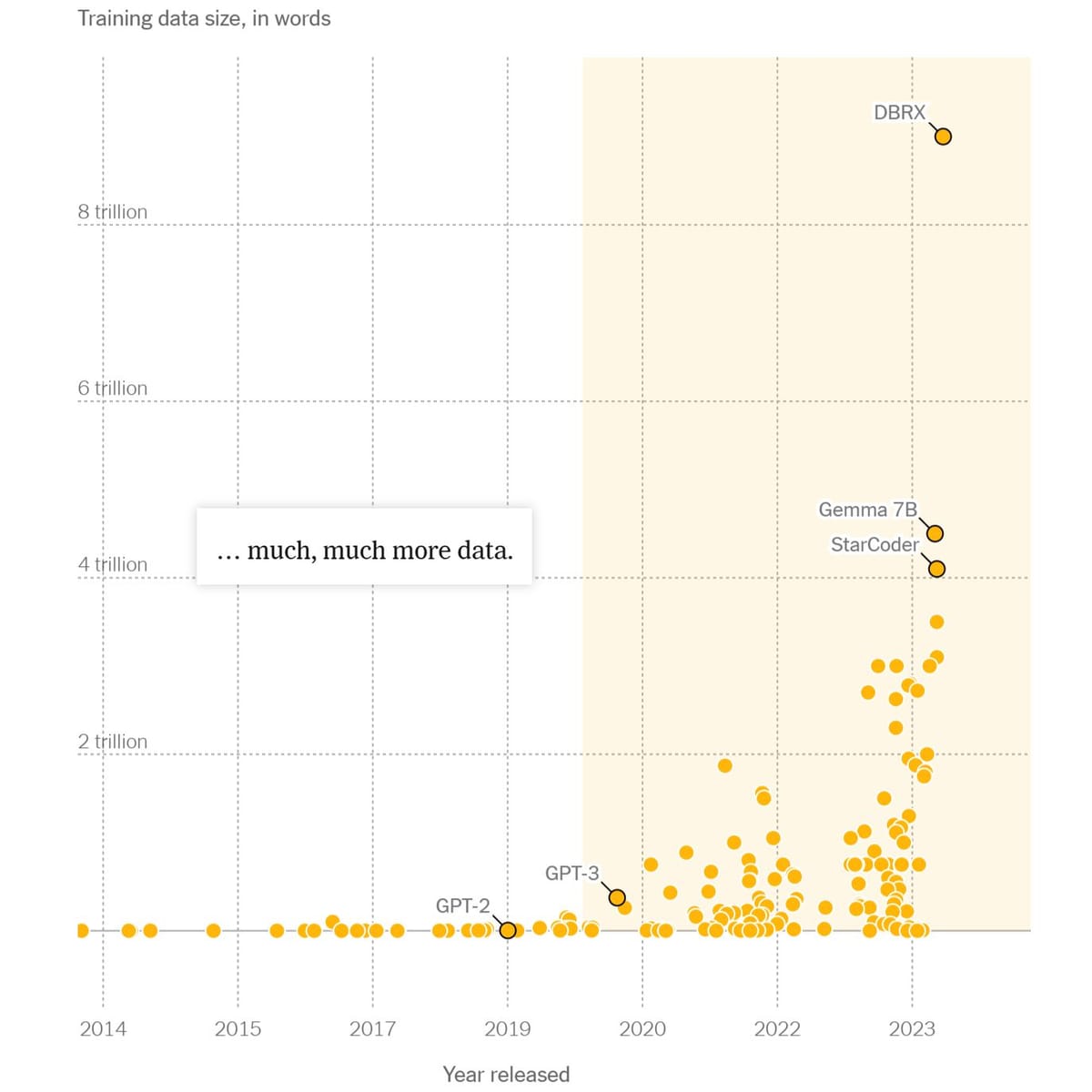
Initially billions (GPT-2), then hundreds of billions (GPT-3), and now trillions of words (DBRX).
Copyright left behind
But what of copyright and doing the right thing? Negotiating licensing deals would take too long, it was decided.
Various examples were cited:
- Lawyer voicing ethical concern met with silence.
- Ethics of using people's creative works glossed over.
Indeed, Google's legal department even asked their privacy team to broaden the language of how consumer data can be used.
It was tweaked and could potentially allow Google to tap "publicly available" Google docs, though Google denies having done that. Yet.
𝗣𝗿𝗼 𝘁𝗶𝗽: Set explicit permission to your files for collaboration; the anonymity of a 'random' URL won't protect you from Google come data collection time.
All out of data
Despite throwing ethics out the window, tech companies could run through all available high-quality data as soon as 2026, according to Epoch, a research institute.
So yup, it will stop in 2026 because there'll be nothing left to take.
What next, then?
Plans are afoot to utilise "synthetic" information, or text, image, and code produced by AI models. There are inherent risks to that - research has shown quality falling quickly. Read "Using AI output to train AI causes MAD" here.
A possible solution: Have 2 AI models working together - one creating, the second as the critic.
Would that work? I have no idea.
Regardless, it's worth noting that all your publicly accessible data is probably not safe. If it's not stolen already.