Human error causes hour-long outage at Cloudflare
Whoops, we did it again.

A single human error brought multiple services on Cloudflare down in an hour-long outage. Here's what happened.
Major CDN provider Cloudflare suffered a significant outage on Friday, and it was caused by a single mistake that also impacted other services.
What happened
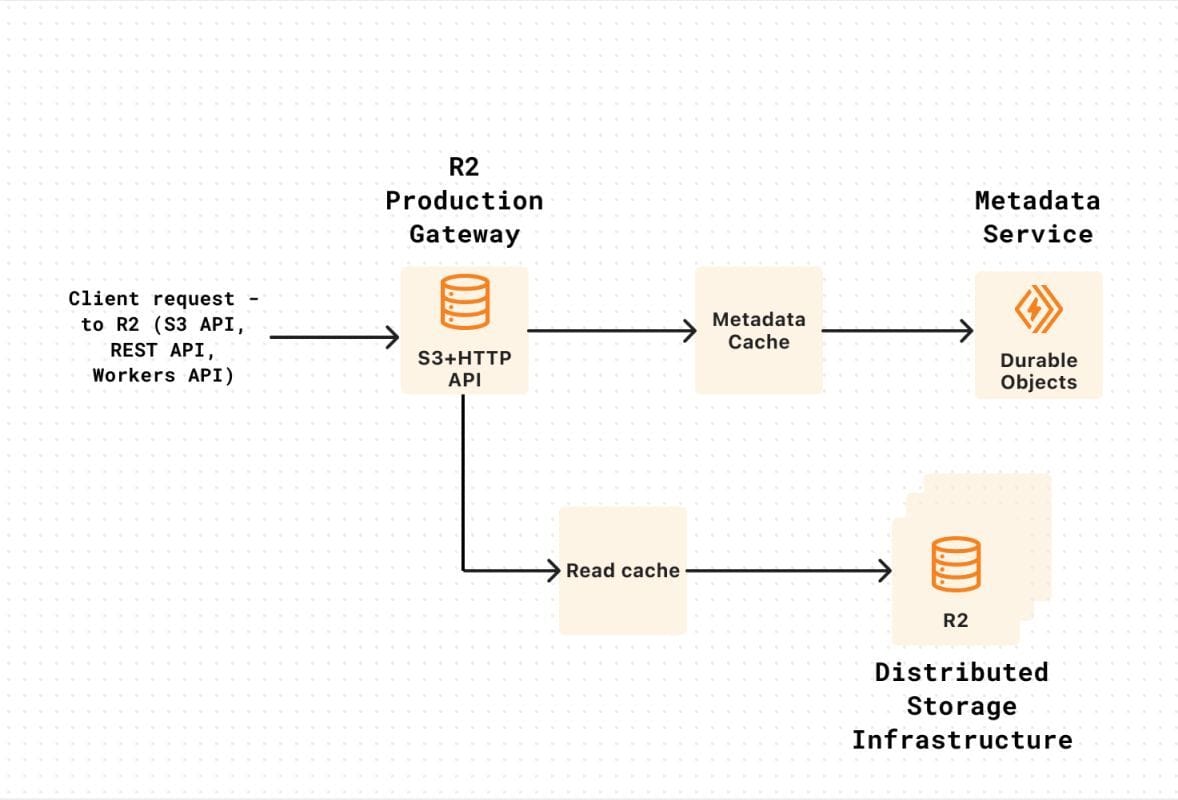
A routine remediation action to disable a storage bucket on Cloudflare's R2 service* saw the entire service brought down for 59 minutes.
Working on an abuse report, a human operator incorrectly disabled the R2 Gateway instead of the problematic endpoint.
This knocked the R2 service offline, including other Cloudflare services that depend on it:
- Stream.
- Images.
- Cache Reserve.
- Vectorize.
- Log Delivery.
*R2 is an S3-compatible object storage service with no egress fees.
Lack of controls
Still, this mistake shouldn't have happened in the first place. To its credit, Cloudflare was quick to publish a detailed blog that identified what went wrong.
- Operator training.
- Abuse system don't differentiate internal systems.
- No control for reversing product disablement action.
Ultimately, the error meant that an operational team much higher up the chain had to be activated to recover the service through a re-deployment.
Thankfully, there was no data loss or corruption as the core R2 service wasn't affected.
SLA: A double-edged sword
Cloud users typically rely on SLAs that cloud providers furnish to determine the likelihood of outages and design their applications accordingly.
But what of applications that depend on more than one cloud service? Won't the risks compound? And how can enterprises account for a more complex failure scenario?
Something worth thinking about for the weekend.
PS: Hat tip to Douglas Mun for bringing it to my attention!



